All Courses
COMING SOON
COMING SOON
COMING SOON
Chains, forks, and colliders
This lesson is all about paths. You’ve already learned what paths are and how to differentiate between direct and indirect paths. In this lesson, you’ll learn to identify three distinct types of paths: chains, forks, and colliders. These are the basic building blocks of any DAG, and they contain only three nodes.
In future lessons, you’ll learn to see that any DAG is just a constellation of these three basic path patterns. Learning to identify chains, forks, and colliders within a more complicated DAG and understanding the implications of each pattern is a fundamental skill for this course.
Chains (Pipes)
A chain (also referred to as a pipe) is a path containing three nodes that takes you from the first node to the third node without changing direction. In the DAG below, you can go from to to without changing direction (i.e., all of the arrows are pointing in the same direction). The variable that sits in the middle of a chain is called the mediator.
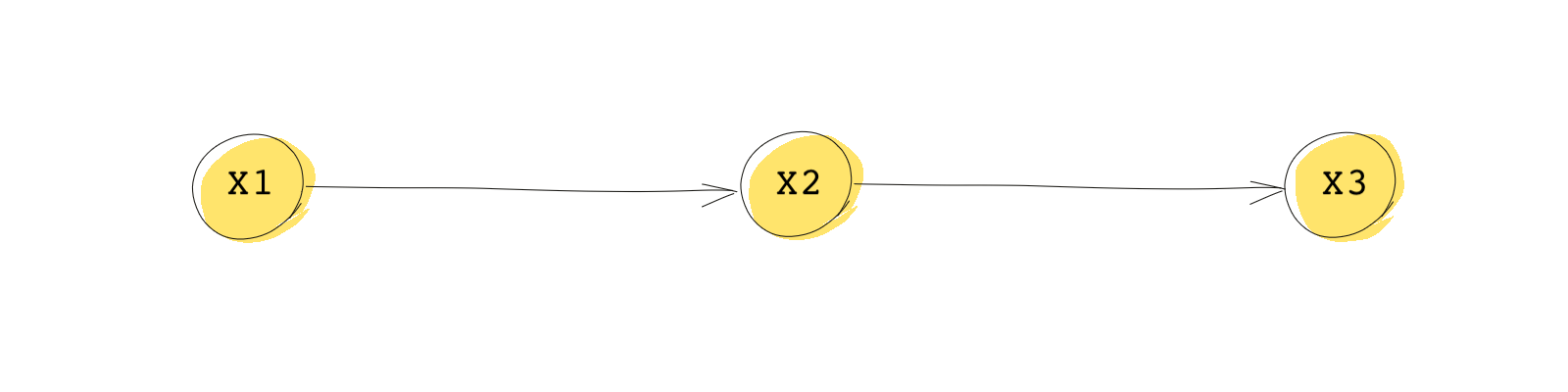
Let’s consider a conceptual example of a chain where is inches of rain in an hour, is the number of rides a Lyft driver gets in an hour, and is the income earned by the driver in that hour. If there is heavy rain one afternoon, we can expect the following sequence of events: more people will want to take a Lyft, so the driver gets more rides, and the more rides the driver gives, the higher the driver’s income will be. Here, causes , and causes , but rain is not a direct cause of the driver’s income. It’s an indirect cause. The significance of a chain is that if we condition on the mediator , then and become independent. In plain English, if we have information about , we do not need to know anything about to make inferences about . If we know the driver got more rides, we don’t need to know anything about the weather, to make inferences about income.
Mathematically, this all looks and sounds much more complicated: the probability of conditional on both and is equal to the probability of conditional only on .
Forks
In a fork, one node is the common cause of the other two nodes. In the fork below, is the common cause of both and .
As an example, think of as the average income of a country, as chocolate consumption in said country, and as the number of Nobel laureates from that country. This is a famous example that you may have encountered in other courses.
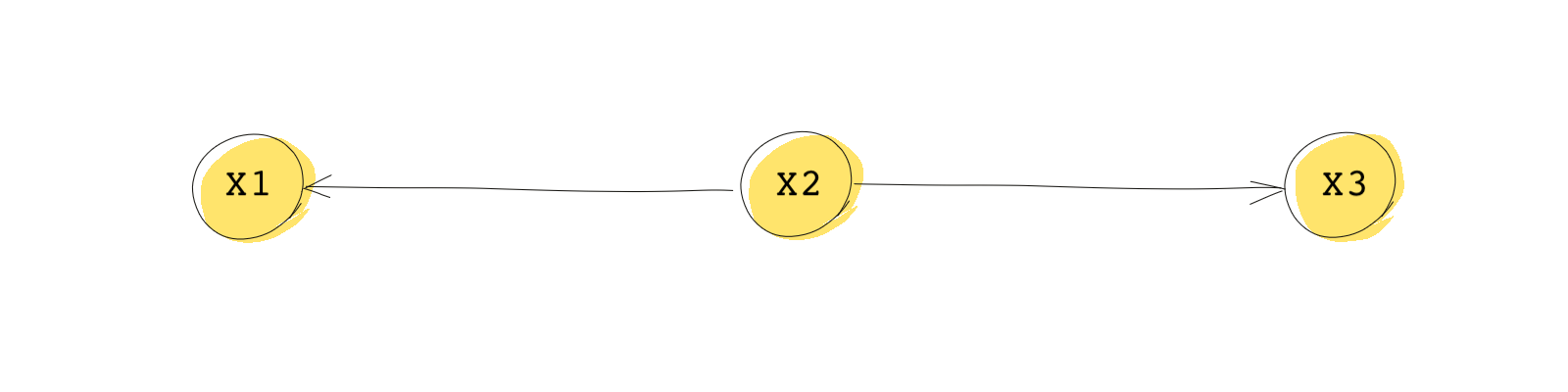
This DAG shows that and are not independent because the same information flows to both of them. However, and will be independent if we condition on .
When thinking about our example this becomes even clearer. If you look at the relationship between chocolate consumption and the number of Nobel Laureates in a country, you find a surprisingly strong correlation (the variables are not independent). This intrigued some researchers and even led a group of medical experts to the following hypothesis: eating chocolate increases cognitive function, which then helps to explain the high number of Nobel laureates in countries where chocolate consumption is high. Notice that this hypothesis would be represented by a chain leading from chocolate consumption to Nobel Laureates with cognitive function acting as the mediator.
But there’s a simpler and likely more reasonable explanation represented, which can be represented by a fork. Chocolate consumption and Nobel laureates share a common cause: how rich a country is. The richer people are in a country, the more likely they are to consume chocolate; the richer people are in a country, the more likely the country is to produce Nobel Laureates. The fork pattern suggests that controlling for should make the other two variables independent (i.e, if you were to look within specific countries you would observe no relationship between chocolate consumption and the likelihood of winning a Nobel Prize.
Mathematically, we can say:
Colliders (Inverted forks)
A collider (sometimes called an Inverted fork) is the opposite of a fork. In a collider, two nodes are each a direct cause of the third node. In the DAG below, and are both causes (a parent) of .
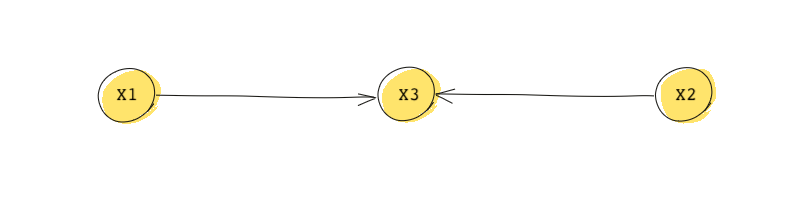
Note here that and are independent. This is because there is no flow of information from one to the other. Besides they don’t receive the same information. In some ways, the information flow between to collides in and that’s why is called a collider.
In the DAG above, however, if we condition on , they become dependent. This is very important and we’ll come back to it in the next lesson. If we unintentionally condition on a collider (thinking we’re removing confounding), we may actually introduce confounding in our analysis.
Imagine we want to estimate the effect of class attendance on academic outcomes (like grades). We know (at least for the sake of our example) that those who attend classes learn more, and therefore, perform better on exams. We also know that the professor of the class we’re talking about has dedicated a portion of her students’ overall grade to class attendance, hence attendance also directly affects grades. What do you think the DAG for this example will look like?
You’re absolutely right! It looks something like this:
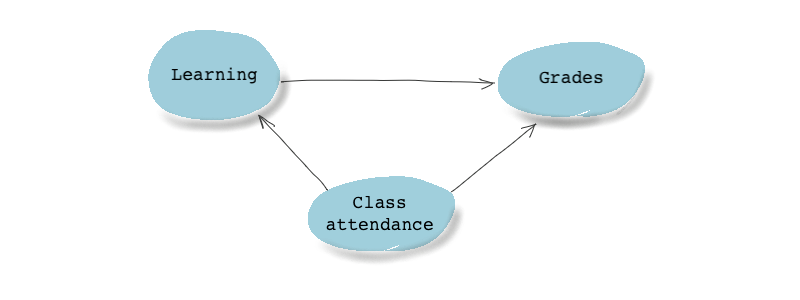
This DAG doesn’t really look like any of the path types we just saw, but look closely and you’ll see that there are two paths between the treatment (class attendance) and the outcome (grades).
- It has a direct path in it: Class attendance Grades.
- And it also has a chain: Class attendance Learning Grades.

Next Lesson
Blocking a path
You'll learn about the basics of causal inference and why it matters in this course.
