All Courses
COMING SOON
COMING SOON
COMING SOON
Back to randomized experiments
Matching and inverse-probability weighting methods are all based on a strong assumption: the ignorability assumption. The set of covariates that we match on (or find weights based on) must satisfy the ignorability assumption for our causal inference magic to work.
We’ve talked about the ignorability assumption quite a bit, but that’s only because our entire analysis rests on this assumption. The implications of the assumption can not be stressed enough. It’s only if our assumptions about ignorability are correct, that we are able to assume away selection bias and proceed forward as if treatment assignment is randomized within each stratum of our sample.
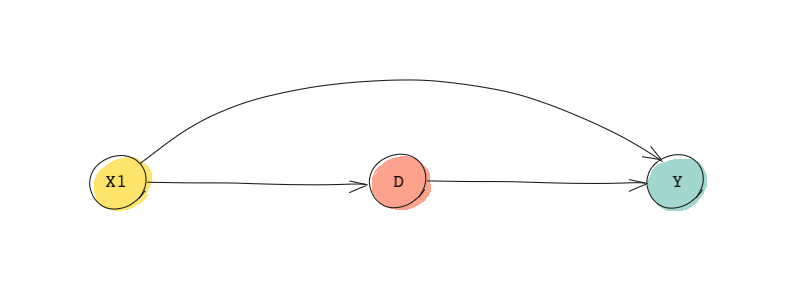
We know that the covariates that satisfy the ignorability assumption are a set of variables that, if controlled for, block all backdoor paths from the treatment to the outcome. For instance, in the familiar DAG below, the path is a backdoor path that needs to be blocked. Therefore, the ignorability assumption requires that we control for the variable .
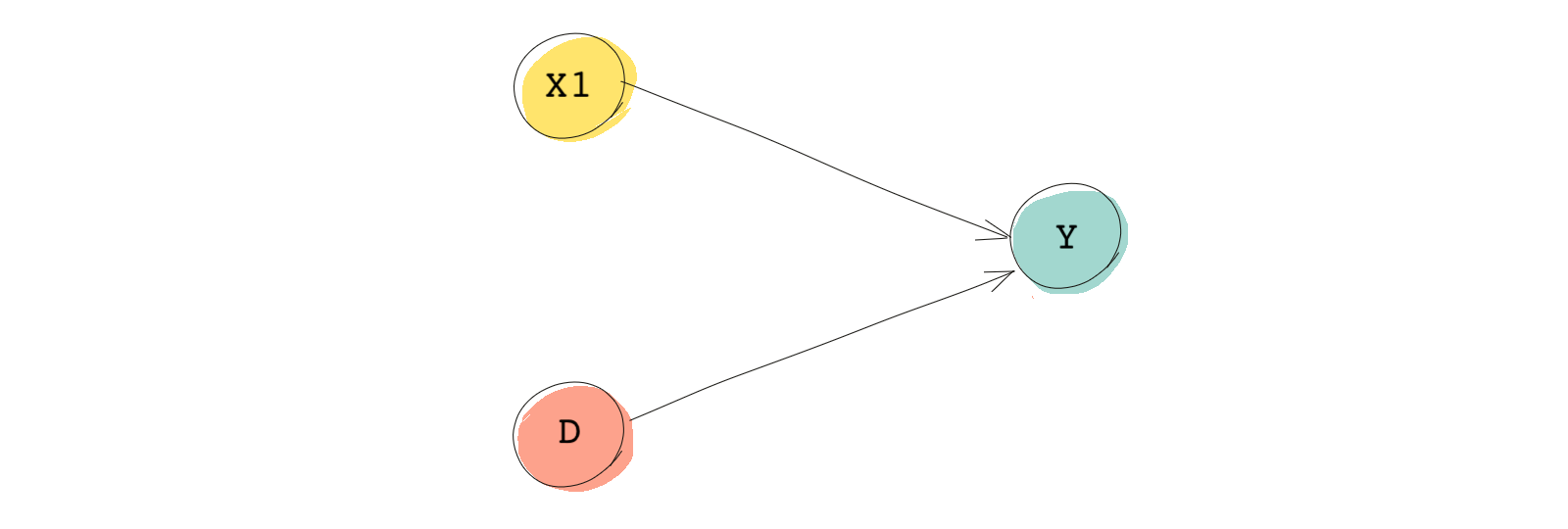
In randomized experiments, by design, the treatment is randomly assigned. Although there might be variables associated with the outcome, they should not be associated with the treatment and the backdoor paths. So if randomization is done right, there shouldn’t be any backdoor paths. An example is shown below. Compare this to the DAG we saw above.
Relatedly, in a randomized experiment, the distribution of covariates in the treatment and control groups should strike a natural balance (i.e., they should be similar). Given this balance, there is no need to control for covariates when estimating the causal effect of the treatment.
These are the reasons why randomized experiments are such a great tool for causal inference. They allow us to circumvent a lot of the analytic work that needs to be done in an observational study.
Unfortunately, randomized experiments are expensive. At times, they are unethical to implement (imagine you wanted to do a randomized experiment on the effects of vaping on health). They can be time-consuming, and sometimes, they are impossible to properly implement. A researcher running an experiment has to design it, wait for the implementation of the design, collect data, and analyze it. In observational studies, however, the data is pre-existing. Furthermore, randomized experiments sometimes suffer from non-compliance issues. We’ll talk about these issues in the next lesson.
This is why we are stuck with observational studies for a lot of questions ranging from epidemiology to economics and psychology.
Just because we work with observational studies instead of randomized experiments does not mean that we can’t estimate causal effects. We learned that DAGs are great tools for identifying the confounders, and once we control for those confounders, causal estimates are a lot more reliable.
We run into trouble in observational studies when we can’t observe our key variables. For instance, the data is already collected and we can’t retrospectively collect a variable. Or when the variables are unmeasurable such as an individual’s motivation or emotional ability.
In this module, we will discuss a method of causal inference that is helpful when there are unobserved confounders: confounders that we identify and that need to be controlled for but are unavailable in the data. In such cases, the ignorability assumption is violated. The method employs instrumental variables (IVs).
Get your ☕️ and let’s get started.

Next Lesson
Intention to treat estimator
You'll learn about the basics of causal inference and why it matters in this course.
